7. Machine intelligence Challenges us to confront our relationship with data
Machine intelligence technology is reliant on data to support both its development and its ability to function for a user in-the-moment. But past failures in data protection have led to rightful concerns from users about the ways their data is active within their experiences. However, a lack of data can also lead to features that underperform, exclude, and even harm. Machine intelligence invites users and tool makers to re-examine their digital products with a view towards data experience design, as well as their own personal relationships with their data.
A user data elephant
There’s an elephant in the room…
So far, machine intelligence has been offered optimistically as the driving technology of our next creative wave. It stands to provide new ways for creatives to engage with their content, new avenues to pursue their ideas, new formats to store and share their output, and new tools and materials for them to express with.
But excitement around these prospects can lead us to ignore the elephant, which is still standing there, and represents a fundamental requirement of machine intelligence technologies: data—including considerable amounts that can come from users.
Our roles and purposes for data
Although user data isn’t a new ingredient of our digital experiences, its roles and purposes have steadily evolved over time. A colloquial attempt at chronicling this could be outlined as follows:
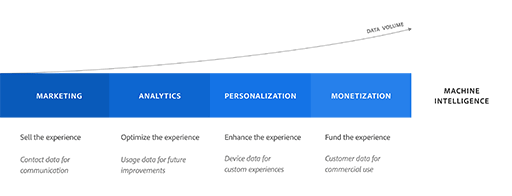
| Marketing | Sell the experience | E.G. Collecting a user’s name and email address to support email marketing. |
|---|---|---|
| Analytics | Optimize the experience | E.G. Tracking usage data of an experience to inform future development. |
| Personalization | Enhance the experience | E.G. Accessing current data—such as time, weather, location, or in-app activity—to drive dynamic experience content. |
| Monetization | Fund the experience | E.G. Capturing user data at scale with intent for commercial use, which supports the user’s experience to be offered financially free-of-charge. |
There’s an implied narrative here that suggests an ever-increasing need for user data at ever increasing scales. This is even more so the case if we consider how digital experience development can subscribe to multiple of these data-driven activities simultaneously.
But while these methods support a reasonable desire to improve and promote experiences, it’s in no way an original statement to say that “with more data comes more challenges”. News of security breaches and data misuse—typically including the loss or theft of user information—are now commonly reported to the public; Who, over the years, have developed a more heightened awareness around their personal data, privacy, and their trust in the products that they use.
That trust is easily eroded and abused. The website haveibeenpwned.com (created by web security expert Troy Hunt) is a free online tool that allows users to search a database of personal email addresses and passwords that have been included in known data breaches.1 The site launched in 2013 with a searchable database of just over 150 million breached accounts. In 2020, that number passed a threshold of 10 billion.2
Our roles and purposes for data with machine intelligence
In trying to predict how machine intelligence might continue this data collection story, it’s easy to imagine scenarios of “big data” harvesting, where algorithms are given the ability to listen, gather, learn, and self-optimize in real-time. But these visions are in-part shaped by inaccuracies that don’t fully recognize the ways machine learning functionalities and data interact with each other. There are two clear data purposes worth acknowledging:
- Data for developing functionality, as part of a training dataset Before a piece of machine learning functionality can be offered to a user it needs to be trained. As shown previously with the COCO dataset, training typically occurs on a large dataset that’s been manually cleaned and labeled ahead of time. More effective datasets are specific in their design, curated towards an intended learning exercise or content domain. Training is also computationally intensive, requiring expensive hardware or cloud server resources. Combined, these factors mean that training can rarely ever occur on a user’s device in real-time while working with their personal data. Although real-time, on-device training isn’t a distant future (and could maybe be achieved with high-end dedicated hardware), any of today’s user-experiences that allude to such activities are either not using machine learning, or are deploying user data as an optimization layer for a feature that’s already been trained on a much larger dataset. It’s useful to emphasize just how intentional dataset construction is around a planned training exercise or learning problem. A mass-collection of “user data for data’s sake” creates high volumes of manual cleaning and curation work, whereas gathering only what’s needed for a defined training activity can be a much more strategic (and cost effective) approach.
- Data for powering functionality, as in-the-moment input Once a machine learning model has been trained it’s no longer in a state of learning, and in many ways exists like any other non-machine learning function: where input drives the creation of output. Certainly, there are key technology differences that inform how input is processed and how output is produced, but the high-level motions are the same. What’s also the same, is that output can only exist when input is given first. For example, someone using a trained machine learning model to “remove the background” from a photo, must first let the feature access the image they want edited. In a scenario where heightened sensitivities around user data are present, a stalemate can emerge. In the case of ‘removing the background’, a user who feels uncomfortable giving access to their file is inadvertently withholding the input data that gives the feature its ability to run. If we consider these similarities of trained models to more traditionally developed functions, it’s fair to argue that a trained machine learning feature makes no more use of someone’s data than any regular feature might. But as products continue to explore cloud-based digital service models, the flow of data that’s powering our experiences becomes important to pay attention to.
Encouragements, benefits, and costs
When faced with questions concerning the collection of user data for machine intelligence, there’s comfort to be found in the fact that, in theory, a machine learning model must first be trained on an existing dataset before it can be used, and that any data provided as momentary input for trained functionalities can be deleted as soon as an output is returned to the user. But there’s one more variable relating to cloud-based services that can significantly impact how user data moves through a machine intelligence context. Specifically, that trained functionalities can be stored and run both on-device and from the cloud.
For basic features, like a simple object detection, running on-device will typically offer faster performance, while also keeping data local with no requirements for an internet connection. However, features take up device storage and memory, and more complex functionalities can quickly consume and outgrow the capabilities of most current devices. This creates conditions where it’s often faster and more efficient for a user’s data to be sent from their device to a feature that’s stored in the cloud. Here, input can be processed faster than it would be locally, and output returned to the user once generated.
The sales pitch is compelling for cloud-based services, with promises of faster performance, fewer demands on device storage and memory, reduced requirements for high-end hardware, and less onus on users to run regular software updates. As network infrastructure like 5G continues to roll-out across the globe, the feasibility of these services also becomes even more realistic. But all of this comes at a cost: our willingness to allow for the movement of user data through our digital experiences.
Though in this same line of thinking, it’s also worth considering the potential costs of not allowing data to move in a machine intelligence context.
Gender Shades: Data-driven innacuracy
Joy Buolamwini is a graduate researcher and computer scientist at the MIT Media Lab. While working on a project in 2015, she was experimenting with a trained facial recognition model. The project was an augmented-reality mirror that would allow anyone to stand in front of it and see a digital mask rendered in real-time on top of their reflection. Testing the functionality on others, the feature would pop a graphical overlay on-screen that outlined their face and key features. But Joy experienced something different when testing the functionality on herself… nothing happened.
The same was true under different lighting conditions, the technology would kick into action as others stood in front of the camera, but then wouldn’t for Buolamwini. After further experimentation a fix was identified: a white theatre-mask. As long as Joy held it over her face the feature would identify her presence. But when the mask was gone, so was she. For a project about digital masks, it was an ironic workaround.3
But what was causing the error? After seeing the functionality work successfully on others, Buolamwini guessed it might be related to the color of her skin. This hypothesis became the basis of a much deeper body of research that was published three years later under the title “Gender Shades”.4
Joy’s study gathered a dataset of over one thousand faces. Each was tagged with their biological gender and also the dermatologist approved “Fitzpatrick skin type classification system”. Once prepared, the faces were then used with machine learning functionalities created by three companies offering gender classification products: Microsoft, IBM, and Face++. The test was simple: would the feature successfully match its gender classification output with the gender assigned in the tagged dataset? Key findings were as follows:
- Overall performance accuracy on the whole dataset was high. Microsoft had the greatest accuracy at 94%.
- When analyzing the results by four sub-groups (lighter males, darker males, lighter females, darker females), all three companies performed better on males than females, and all three companies performed the worst on darker females.
The fact that Buolamiwni fit into the “darker females” sub-group confirmed that her experience with the theatre-mask was part of a trend: “darker females” were more likely to experience errors when trying to use the facial recognition products included in the test.
Reflecting on the study’s findings in a video that accompanied the published paper, Buolamwini had this to say: “While more research is needed to explore the specific reasons for the accuracy differences, one general issue is the lack of diversity in training images and benchmark datasets… Companies should do better with commercially sold products, especially since the machine learning techniques that have made gender classification possible, are applied to other domains… like predictive analytics. Predictive systems can help determine who is hired, granted a loan, or what information a particular individual sees. These data centric technologies are vulnerable to bias and abuse.”5
Underperformance, exclusion, and harm
In the context of training datasets, bias is a product of absence or imbalance.
Our ability to create machine intelligence that’s capable of interpreting the semantic world requires comprehensive and representative datasets. For instance, a feature that “selects the sky” from an image is only as good as the examples of sky shown during training. If this sky dataset includes more images of outdoor scenes than it does indoor (where sky might be seen through a window), an imbalance is created that can lead to higher rates of error for anyone trying to use the feature with indoor images. Similarly, if this same dataset fails to include examples of the sky at night, attempts to use the feature with any nighttime images will likely result in the algorithmic conclusion that there’s no sky in the photo to select.
This example, as well as the scenarios described by Buolamwini, highlight three problematic outcomes of imbalanced datasets:
| Underperformance | Training datasets that are imbalanced across applicable content groups can produce inconsistent model performance, where less-represented content is subject to higher rates of error. | E.G. Where a trained model that can generate images of cars, creates lower-fidelity output when the car is facing forward, compared to the higher-fidelity output it creates when the car is facing sideways. |
|---|---|---|
| Exclusion | Training datasets that are missing applicable content groups can produce blind spots in trained functionality, where a feature’s ability to successfully interact with an element of that group is removed. | E.G. Where a model that’s been trained to scan a photo library and auto-tag images that contain fruits, never tags any bananas despite their appearance in multiple images. |
| Harm | Trained functionalities that fail to perform accurately, can misfire in ways that cause a user to be insulted, misrepresented, or devalued. | E.G. Where a model trained to generate edits to human faces, keeps automatically adding hair to the photo of a bald user. The user is self-conscious of their baldness, and the functionality is asserting a standard where hair is assumed for all humans. Later, another functionality classifies the user’s same image with the tag “infant”. |
When faced with the underperformance, exclusion, and harm that can occur in machine intelligence functionalities, data is an essential combatant. It allows us to practically address to the imbalances and absences we encounter. But where should that data come from?
The user data elephant and stalemate are back.
A user data stalemate
There’s a concept in open-source development referred to as “Linus’s Law”. Coined by Eric S. Raymond and named after Linus Torvalds (both previously mentioned), the law proposes that “given enough eyeballs, all bugs are shallow”.6 In the case of software development teams, if the combined skill set of a group isn’t enough to solve for a particular bug, then that bug becomes “deep”. Raymond, however, argues that in open-source environments, exposing the bug to a global and diversely skilled pool of contributors increases its likelihood of being found and fixed by a developer with the expertise to do so—making it “shallow”.
In reflecting how we might tackle the machine intelligence dataset problems of absence and imbalance, Linus’s Law suggests a possible strategy. Where a small team constructing a dataset might encounter “deep” difficulties—because available data might be limited or access to original source material problematic— “deep” can be made “shallow” if a diverse and global user base is empowered to contribute their data to difficult areas.
But this is uncomfortable. Users have a rightful wariness of how their data can be active on their devices and in their browsers (often invisibly), along with justified concerns about the negative outcomes caused by losing control of personal data.7 At the same time, the movement of data in our experiences remains a vital infrastructural component of machine intelligence, and a way of supporting next generation functionalities that work well for everyone… So how do we move forward?
Looking practically for data experience
The following is a set of starter questions intended to help identify characteristics of machine intelligence features that might impact a user’s data experience. For example, knowing if a piece of functionality is stored on-device or in the cloud, confirms a user’s need for a data connection and if their content is ever potentially leaving their device.
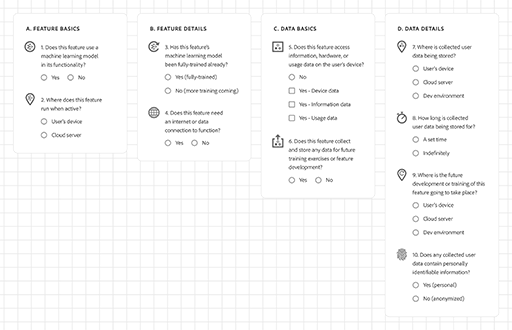
This concept of data experience design warrants a much greater examination. Machine intelligence challenges us to confront our relationship with data; to be more informed of how data interacts with technology; to increase our awareness of when data is active within an experience; and to be proactive in our response to moments of underperformance, exclusion, and harm in trained functionalities. Building a stronger practical awareness of our data as it moves through our experiences is something we can start to do today.
Further thinking
Ask yourself or discuss with others.
- Chances are, an email address or a password you use is included in the haveibeenpwned database. How does the idea of your data being leaked or stolen make you feel?
- Have you ever worked on a project that was informed by data in some way? Which role and purpose from Figure 1 is most applicable, and how did it help you move forward in the project?
- Think of a time you’ve personally experienced a feature that underperformed, made you feel excluded, or caused harm in some way? What flaws in the experience were at the heart of that moment, and what improvements could help prevent it from happening again?
- Do the practical questions at the end of the piece help inform your understanding or awareness of how and why your data is active in an experience? Would you add or remove any questions?
References
- Hunt, Troy. Have I Been Pwned?, haveibeenpwned.com. Accessed 30 June 2021.
- Whittaker, Zack. “How Have I Been Pwned Became the Keeper of the Internet's Biggest Data Breaches.” TechCrunch, 3 July 2020, techcrunch.com/2020/07/03/have-i-been-pwned/. Accessed 30 June 2021.
- Coded Bias. Directed by Shalini Kantayya, performance by Joy Buolamwini, 7th Empire Media, 2020, netflix.com/title/81328723. Accessed 30 June 2021.
- Buolamwini, Joy, Gebru, Timnit. “Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification.” Proceedings of the 1st Conference on Fairness, Accountability and Transparency, PMLR 81:77-91, 2018. pp. 77–91. proceedings.mlr.press/v81/buolamwini18a.html. Accessed 30 June 2021.
- Joy Buolamwini, Joy, Jimmy Day “Gender Shades.” YouTube, uploaded by MIT Media Lab, 9 Feb. 2018, youtube.com/watch?v=TWWsW1w-BVo. Accessed 30 June 2021.
- Raymond, Eric S. The Cathedral and the Bazaar: Musings on Linux and Open Source by an Accidental Revolutionary. O'Reilly, 2001. p. 43.
- Auxier, Brooke, et al. “Americans and Privacy: Concerned, Confused and Feeling Lack of Control Over Their Personal Information.” Pew Research Center, 15 Nov. 2019, pewresearch.org/internet/2019/11/15/americans-and-privacy-concerned-confused-and-feeling-lack-of-control-over-their-personal-information/. Accessed 30 June 2021.