5. Machine intelligence Reimagines assets and file formats
For an increasingly iterative and collaborative world, digital file management and version control are persisting challenges. Solutions have emerged in spaces like open-source development, but the unique properties of creative file formats are harder to address. Machine intelligence offers new ways for us to monitor and track our creative content, and the potential for a full reimagining of creative assets and file formats.
A constantly changing bookshelf
In 1995, the United States Library of Congress officially launched the National Digital Library Program, undertaking an effort to digitize primary source materials from a collection that today exceeds 170 million catalogued items.1,2 In the years following, these digital collections grew beyond the library’s physical holdings to also include “digital-born” items, such as e-publications, smartphone images, and select archives of the web.3
As any creative professional who’s spent time organizing their project files and folders can attest, maintaining an active system for file organization is a project unto itself: How should files and folders be named? Is there a method for version control? Does active work get stored differently than completed work? Should file formats be consciously regulated?
Writing for the Library’s online blog in 2012, digital preservation expert Leslie Johnston notes how hard it can be to manage the scale and scope of digital files:
“Here’s what I can say: the Library of Congress has more than 3 petabytes of digital collections. What else I can say with all certainty is that by the time you read this, all the numbers—counts and amount of storage—will have changed.”4
Where physical media takes a static and fixed form that’s more tangibly managed and organized, Johnston highlights the complexity that comes from the living nature of digital files—like a constantly changing bookshelf where not only the number of books is changing, but also the contents of the books themselves as they’re updated, edited, shared, or even overwritten.
Data containers with a living nature
To better inform the ways we might create, catalogue, and organize our digital files in the next creative wave, it can be helpful to first assess what a file actually is: a simple container of data, that software is able to read [decode] and write to [encode].
Data can be encoded in different ways, creating a number of basic file format types—for example, audio data is encoded differently to textual data. Format types can also be bundled together as a single file, known as a generic file type—for example, certain video formats are technically generic, grouping video data alongside its corresponding audio and subtitle files for software to then playback all at once.
Below, is a summary of the basic universal structure of a file alongside its basic format types, as categorized by the US Library of Congress for their digital archives.5
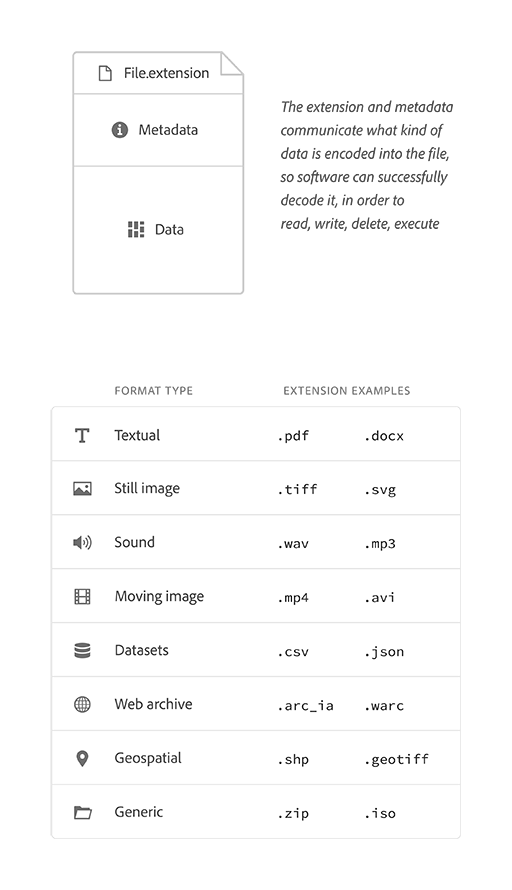
The design of this system may appear logical and simple, and even comparable to file organization systems of the analogue world. But acknowledging its digital, living nature (as Johnston does), reveals a number of user challenges and needs. In particular: a user’s need to communicate file contents, manage changes as they occur, and support multiple individuals working in a file simultaneously.
In response to these needs, there are already a number of built solutions available today. One, most notably, is linked directly with perhaps the most significant ideology to emerge from computing history to-date, known as open-source.
An open-source response to living nature
It cannot be overstated how impactful the internet has been as an incubator for disruption and a driver of scale. In the 1990s, computer programmers and software developers experienced this first-hand on the topic of how software could best be developed, an account of which is documented in Eric S. Raymond’s influential essay, “The Cathedral and the Bazaar”.
In the piece, Raymond outlines the open-source approach to development, where anyone can access a project’s source-code and use the internet to “… create an open, evolutionary context in which feedback, exploring the design space, code contributions, bug-spotting, and other improvements come from hundreds (perhaps thousands) of people.”6
But, a large-scale coding collaboration, facilitated via the internet, and open to anyone (of any skill level) to contribute, also exposes and amplifies the user needs surrounding digital file management. The Linux kernel project originally accepted contributions via an email list, with Torvalds personally incorporating updates into the main source code. But as the project grew, so did the need for a more sustainable method of file management. In 2005, Linus and team created Git, an open-source version control system for managing changes and contributions to project files.7
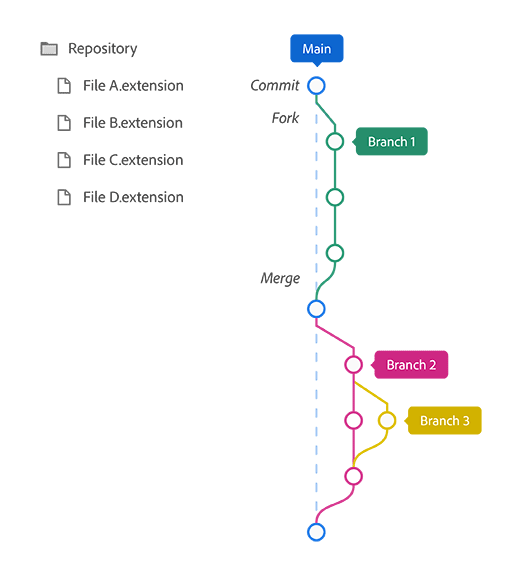
As visualized above, Git utilizes an approach that allows anyone to “fork” a copy of the entire project folder (aka. “repository”) into its own “branch”. Here, files can be edited and added to without fear of overwriting the contents of the “main” branch. At important progress steps, project files can be snapshotted with a “commit”, and when key updates within a branch are completed, they can be submitted to the project owner for review, approval, and then merging back into the main branch. As a project develops over time, Git maintains a complete history of every commit, fork, and merge, as well as a record of every file change down to the exact line of code.
The Linux kernel began in 1991 as 88 files and just over 10,000 lines of code. 29-years later, and thanks to over 20,000 contributors, the project consists of almost 70,000 files, 29.4 million lines of code, and recently celebrated its 1-millionth commit.7 A constantly changing bookshelf.
The problem with creative files
“Filename-V5-FINAL-corrected-alt2-FINAL-final.pdf” is a commonly-shared meme among creative professionals, that’s perhaps best explained by Adobe Principal Designer Khoi Vinh: “Designers still use shockingly manual and even arcane methods of managing versions”.8
But if the world of open-source stands as proof for the viability of fork-and-branch file management at scale, then why is it that similar approaches aren’t the established standard in creative software?
To answer, it’s important to note that one key factor allowing a version control system like Git to succeed, is that the majority of contributors are working in the same data languages that their files are encoded in. For example, if a project contains an .html file then the contributor is likely writing in some form of web code. This isn’t the case for many creative file formats. A user creating vector illustrations will most likely work visually in a tool like Illustrator, and although the file they’re building is technically code (such as SVG), their software is constructing that code on their behalf.
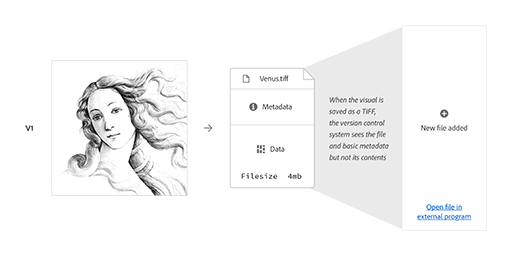
The following example shows how a version control system like Git would handle a basic vector illustration. As version one of the image is introduced, the system accepts it as 41 lines of code totaling 10kb in size. When changes to the visual are saved as a version two, the system continues to operate at a code-level—identifying lines that have been added, removed, or stayed the same—and now recognizes a 5kb file consisting of 21 lines of code.


But this system isn’t equipped to recognize changes at a visual level. A creator might choose this style of file management as a more efficient means of storing versions, but manual work is still required if they want to document what’s changed visually. In the example, it’s not clear at a code-level that the face illustration has been simplified and that the style of the background box has been changed. Here, the tool’s inability to see the work as the creator does reveals a language gap in reverse.
This gap becomes more apparent in the face of file formats that aren’t as easily read by version control systems. This next example shows what happens when a bitmap image is observed by the same system. It recognizes activity at a file level but is unable to see anything at a contents level. As a result, users only see the message “This file has changed”.

So far, we’ve outlined the basic construct of digital files and their associated challenges of version control and file management systems. When looking to fork-and-branch solutions such as Git, we’ve also acknowledged that these systems struggle to read creative file formats in ways that are meaningful to a user’s creative content.
But where might machine intelligence help change all of this?
Ways of seeing: Computer vision
Computer vision is a field of exploration in machine learning that’s focused on the ways information can be pulled from visual content. With tasks ranging from basic object recognition and image captioning, to the creation of new forms of visual analysis, machine intelligence is making rapid advancements in its ability to “see”.
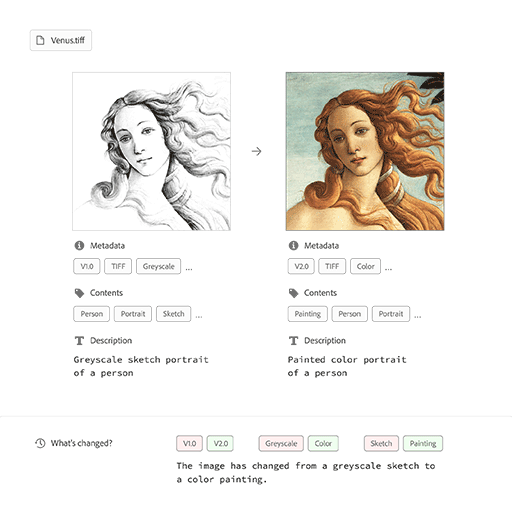
This progress allows for a direct response to the limitations of today’s file management systems. Below, the previous example is re-visualized, but now in the context of a system (albeit a basic one with no real interface) that’s better equipped to observe the user’s visual. Through basic recognition of content and style aesthetic, this system identifies the change from greyscale sketch to color painting.
Reimagining files as creative blueprints
It’s fair to argue that the intelligent functions shown above are passive…reactive responses to content changes with output that only ever lives alongside a file. But these technologies are also capable of generating forms that live more actively inside files too.
Segmentation maps are visual overlays made-up of colored shapes that communicate image content. These shapes can be drawn and labeled by a machine learning model that’s been trained to recognize specific content elements, as taught via an example dataset. Similar to architectural blueprints, a segmentation map can serve multiple purposes:
- First, as a portable description of a composition. Creative file formats are often demanding of a user’s storage and CPU, similar to how a physical building is demanding on space and materials. But where a building is unable to be duplicated for the purposes of versioning, its blueprint provides a lightweight record that’s easily stored, iterated, and shared.
- Second, as an instructional guide for how a composition should be made. As machine intelligence continues to advance in its generative capabilities, the different ways a user might guide that generation process could be compared to an architect specifying the shapes and materials a building is constructed with.
This concept of blueprints is significant. Today, the structure of many creative file formats wouldn’t be described as such, but instead as a container for the user’s complete composition. However, in a creative environment where files do act as blueprints for machine intelligence, assets and file formats start to become reimagined.
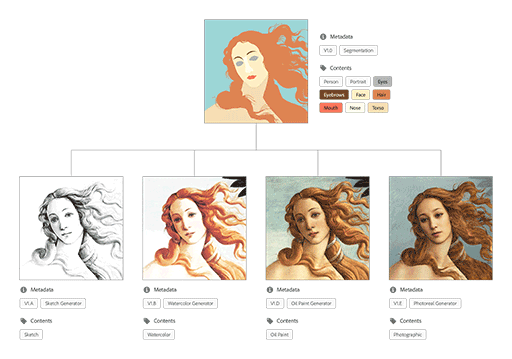
Reimagining files as creative systems
The visual above displays a creative pipeline. It begins with a segmentation map, where a user has outlined a general composition and even assigned certain materials to its different areas. This information is easy for a computer to store and read, and communicates in the language of the content. But it isn’t the final image a user intends for an audience to see. Extending from the segmentation are a series of branches that lead to stylistic variations, as generated by possible machine intelligence models that have been trained on different visual art styles.
In this reimagining, our user problems of file management and version control are actively answered, and new ways of interacting with file contents are made available.
But it’s also at this point that the traditional concept of what amounts to a “file” comes into question. Instead of showing a document structure, this workflow shows a series of author-able components, which together drive the real-time visual output of machine intelligence functionalities. Similar to the architect, users of this type of workflow are now defining a living creative system. A flexible system of this type also challenges our definition of a creative asset. For example, what if a visual asset could be built to render itself differently depending on a viewer’s context—such as location, time of day, device speed, or even personal preferences? Is this a tool capable of outputting many assets, or is this a single asset embracing a new kind of content responsiveness?
One more question: If machine intelligence enables these kinds of file format and asset reimaginings in the next creative wave, then does the role of the creative start to get reimagined as well? After all, how should a creative balance being a maker of art and assets, against being an architect of creative systems and dynamic tools?
Further thinking
Ask yourself or discuss with others
- How do you organize your creative files, and how do you manage versions today?
- We all have a file format horror story where something broke or refused to open. What’s yours?
- How do you hope machine intelligence might help you manage files and versions in the future?
- Describe your ideal creative file format. One that’s perfectly suited to the kinds of projects you work on.
References
- The Library of Congress. “Library of Congress National Digital Library Program.” memory.loc.gov, memory.loc.gov/ammem/dli2/html/lcndlp.html. Accessed 30 June 2021.
- The Library of Congress. “About the Library, Fascinating Facts.” loc.gov, loc.gov/about/fascinating-facts/. Accessed 30 June 2021.
- Jakeway, Eileen. “Metaphors for Understanding Born Digital Collection Access: Part I”, blogs.loc.gov/thesignal/, 20 Aug. 2020, blogs.loc.gov/thesignal/2020/08/metaphors-for-understanding-born-digital-collection-access-part-i/. Accessed 30 June 2021.
- Johnston, Leslie. “A “Library of Congress” Worth of Data: It’s All In How You Define It”, blogs.loc.gov/thesignal/, 25 Apr. 2012, blogs.loc.gov/thesignal/2012/04/a-library-of-congress-worth-of-data-its-all-in-how-you-define-it/. Accessed 30 June 2021.
- The Library of Congress. “Sustainability of Digital Formats: Planning for Library of Congress Collections.” www.loc.gov/preservation/digital/, loc.gov/preservation/digital/formats/content/content_categories.shtml. Accessed 30 June 2021.
- Raymond, Eric S. The Cathedral and the Bazaar: Musings on Linux and Open Source by an Accidental Revolutionary. O'Reilly, 2001. p. 64.
- Vaughan-Nichols, Steven J. “Commit 1 Million: The History of the Linux Kernel.” ZDNet, 26 Aug. 2020, zdnet.com/article/commit-1-million-the-history-of-the-linux-kernel/. Accessed 30 June 2021.
- Vinh, Khoi. “Design Tools News No. 7.” Subtraction.com, 30 Sept. 2015, subtraction.com/2015/09/30/design-tools-news-no-7/. Accessed 30 June 2021.